



Software Diagnosability - Introduction
Software Diagnosability is an important aspect of operability and targets precise and fast identification of problems
You are operating a business critical application. To support customer's demanded for "High Availability"
- or even "Continuous Availability" -
- to minimize interruption of service
- and maximize availability.
- All hardware- and network components are redundant.
- The database operates on an "active/active" or "hot/hot" database cluster.
Indeed, you did spend a lot of money on hardware - and probably even more on hardware-dependent licenses.
However, users are reporting that the application does not respond, or wrong results or wrong error messages.
Unfortunately the Monitoring system does not report anything.
For re-establishing the application service you need
- to identify (to diagnose) the root cause for application not responding
- in shortest possible time frame!
Activating debug mode for the complete system resulting in Gigabytes of trace files per minute and severely slowing down the application is not your preferred choice - especially not if activating debug mode requires an application restart.
Software Diagnosability - Requirements
The application shall provide means to diagnose the problems online,
- without having severe impact on the running system
- even under high production load.
Ideally you want to activate debug mode / trace mode for exactly one user but across all components (web server, application, database). And that without restarting the complete system.
If customer's support is expected to understand and interpret the output, this will of course require sufficient documentation of the end-to-end request / response flow through the system. Otherwise the application vendor needs to be contacted.
The mind-map below provides a structured presentation of requirements for diagnosis:Zoom picture for better resolution
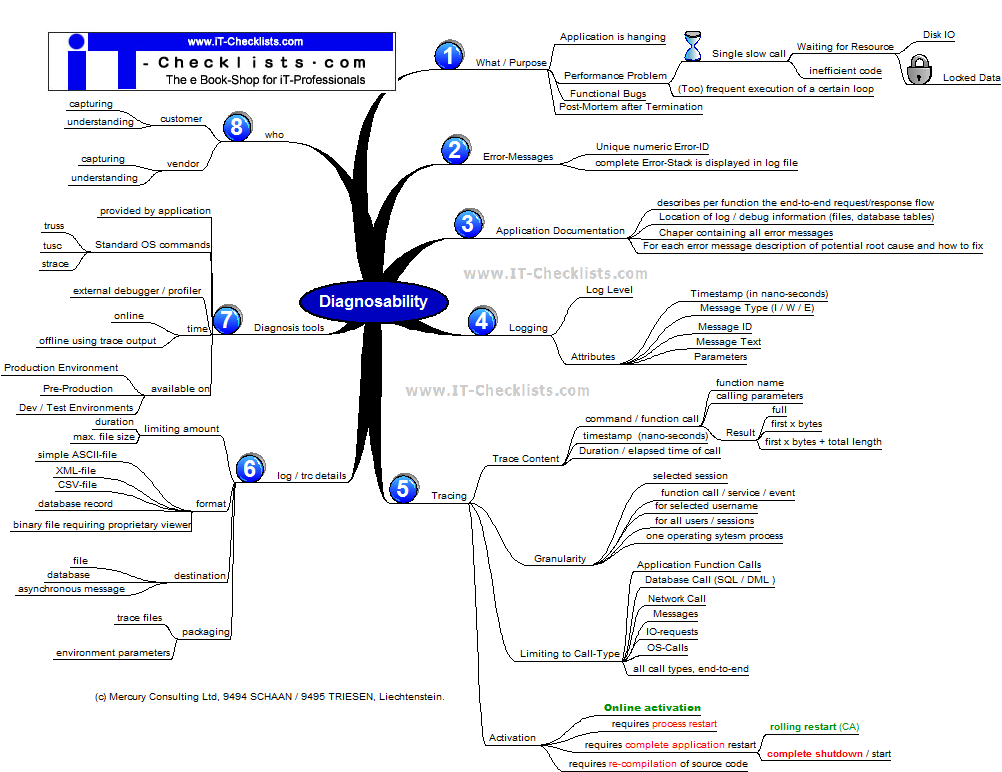
| Branch | Detail |
|---|---|
| [1] What / Purpose | Application is hanging: Purpose of diagnose is to identify the root cause and fix the problem.
Performance Problem: Mostly not reproducible on a development or test system. Activating extensive trace / debug mode system wide will even increase the performance problem. Therefore details from branch [5] are very important! Functional Bug: With some luck this can be reproduced on a development or test system, but that's not guaranteed. In case that you can't reproduce it in a development or test system, you need to diagnose the root cause on the production system. Post-Mortem: A single process or the complete system has terminated before, but system is again up and running. Purpose of the Post-Mortem is to identify the root cause and to derive recommendations to prevent re-occurrence. |
| [2] Error Messages |
|
| [3] Application Documentation |
|
| [4] log / trace details |
|
| [5] Tracing | Activating tracing system wide for a large application with thousands of users will result in severe performance impact and huge trace information, making it difficult to find the problem searched for.
|
| [6] log / trace details |
|
| [7] Software Diagnosis Tools |
|
| [8] Who | Customer: Tools are documented, customer can use those; However without recurring practising customers support staff might loose valuable time to find the most appropriate options.
Alternatively customer captures detailed trace information, and sends those files to vendor's support for further analysis. Vendor: Tools are not documented, the vendor will provide commands and parameters to be used based on actual situation. |